문제
온라인 저지에 가입한 사람들의 나이와 이름이 가입한 순서대로 주어진다. 이때, 회원들을 나이가 증가하는 순으로, 나이가 같으면 먼저 가입한 사람이 앞에 오는 순서로 정렬하는 프로그램을 작성하시오.
입력
첫째 줄에 온라인 저지 회원의 수 N이 주어진다. (1 ≤ N ≤ 100,000)
둘째 줄부터 N개의 줄에는 각 회원의 나이와 이름이 공백으로 구분되어 주어진다. 나이는 1보다 크거나 같으며, 200보다 작거나 같은 정수이고, 이름은 알파벳 대소문자로 이루어져 있고, 길이가 100보다 작거나 같은 문자열이다. 입력은 가입한 순서로 주어진다.
출력
첫째 줄부터 총 N개의 줄에 걸쳐 온라인 저지 회원을 나이 순, 나이가 같으면 가입한 순으로 한 줄에 한 명씩 나이와 이름을 공백으로 구분해 출력한다.
| 예제 입력 3 21 Junkyu 21 Dohyun 20 Sunyoung |
예제 출력 20 Sunyoung 21 Junkyu 21 Dohyun |
해결 방법
이 문제의 경우도 앞선 문제와 크기 다르지 않다.
정렬하는 인자가 나이와 가입순으로 바뀌었을 뿐이지 지난 정렬문제에서 썼었던 다인자 정렬방식을 그대로 쓰면될 듯 하다.
문제는 이번엔 정렬 요소는 2개인데 나이값에 따라 따로 이름을 저장해야한다는 점이다.
필자는 이 문제를 풀 때 정렬 요소를 2개에서 1개로 줄였다.
무슨 말이냐면 나이 순으로 정렬하되 나이가 같으면 가입한 순으로 정렬을 하라고 되어있는데 이때 LinkedhashMap을 쓰면 가입한 순번을 따로 인자로 둘 필요없이 자연스레 가입한 순서대로 출력이 된다.
따라서 인자가 2개에서 1개로 줄었기 때문에 예전처럼 map을 써서 나이(key) - 이름(value)로 저장하면 시간도 빠르고 잘 정렬될 것이다.
그래서 프로그램의 동작과정은 다음과 같다.
1. 나이(key) - 이름(value) 형식의 map으로 값들을 입력받는다.
2. 나이(key)를 배열로 리턴한 뒤 정렬한다.
3. 정렬된 나이순대로 이름을 map에서 가져와서 문자열에 추가한다.
1.
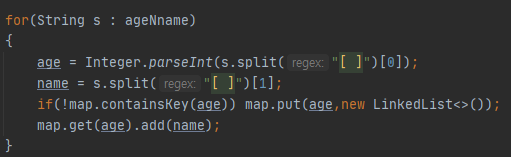
2.

3.

테스트용 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public static String makerandom2(int n) throws IOException
{
Random rand = new Random(System.currentTimeMillis());
StringBuffer str = new StringBuffer("");
FileReader fr = new FileReader(new File("words.txt"));
BufferedReader bufferedReader = new BufferedReader(fr);
String line = "";
String[] strArray = new String[466550];
for(int j = 0; (line = bufferedReader.readLine()) != null ; j++) {strArray[j] = line;}
int lineNum;
int age;
str.append(n+"\n");
for(int i = 0 ; i < n ; i++)
{
lineNum = rand.nextInt(466550);
age = rand.nextInt(199)+1;
str.append(age + " " + strArray[lineNum] + "\n");
}
return str.toString();
}
|
cs |
위 코드는 저번 코드에서와 마찬가지로 words.txt에서 1개를 빼오고 1~200까지의 수 중 랜덤으로 1개를 골래서
"나이 단어" 순으로 n개의 문자열을 생성해주는 코드이다.
words.txt link : github.com/dwyl/english-words/blob/master/words.txt
위 코드를 이용해 10만개의 문자열을 생성하고 우리가 작성한 코드에 넣어서 실행해보았더니

위와 같은 실행시간이 도출되었다.
소스코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
import java.io.*;
import java.util.*;
public class Main
{
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
public static String SortByAge() throws IOException
{
int n = Integer.parseInt(br.readLine());
Map<Integer, List<String>> map = new LinkedHashMap<>();
int age;
String name,s;
for(int i = 0 ; i < n ; i++)
{
s = br.readLine();
age = Integer.parseInt(s.split("[ ]")[0]);
name = s.split("[ ]")[1];
if(!map.containsKey(age)) map.put(age,new LinkedList<>());
map.get(age).add(name);
}
Integer[] sortedAge = map.keySet().toArray(new Integer[0]);
Arrays.sort(sortedAge);
StringBuffer sb = new StringBuffer("");
List<String> tmp;
for(int a : sortedAge)
{
tmp = map.get(a);
for(int i = 0 ; i < tmp.size() ; i++) sb.append(a + " " + tmp.get(i) + "\n");
}
return sb.toString();
}
public static void main(String args[]) throws IOException {
bw.write(SortByAge()+"");
bw.flush();
bw.close();
}
}
|
cs |
느낀점
만약 지금까지의 문제들을 착실히 풀어왔다면 그리 어렵지 않은 문제였다.
특히나 LinkedHashMap을 이용한 것이 신의 한수였다.
'백준 온라인 저지 문제풀이 > JAVA' 카테고리의 다른 글
| [baekjoon 1181번] 정렬 - 단어 정렬 (0) | 2021.03.27 |
|---|---|
| [baekjoon 11650,11651번] 정렬 - 좌표 정렬하기 1, 2 (0) | 2021.03.02 |
| [baekjoon 1427번] 정렬 - 소트인사이드 (0) | 2021.03.01 |
| [baekjoon 2108번] 정렬 - 통계학 (0) | 2021.02.27 |
| [baekjoon 1436번] 브루트 포스 - 영화감독 숌 (0) | 2021.02.18 |