[baekjoon 2108번] 정렬 - 통계학
문제
수를 처리하는 것은 통계학에서 상당히 중요한 일이다. 통계학에서 N개의 수를 대표하는 기본 통계값에는 다음과 같은 것들이 있다. 단, N은 홀수라고 가정하자.
- 산술평균 : N개의 수들의 합을 N으로 나눈 값
- 중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값
- 최빈값 : N개의 수들 중 가장 많이 나타나는 값
- 범위 : N개의 수들 중 최댓값과 최솟값의 차이
N개의 수가 주어졌을 때, 네 가지 기본 통계값을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 500,000)이 주어진다. 그 다음 N개의 줄에는 정수들이 주어진다. 입력되는 정수의 절댓값은 4,000을 넘지 않는다.
출력
첫째 줄에는 산술평균을 출력한다. 소수점 이하 첫째 자리에서 반올림한 값을 출력한다.
둘째 줄에는 중앙값을 출력한다.
셋째 줄에는 최빈값을 출력한다. 여러 개 있을 때에는 최빈값 중 두 번째로 작은 값을 출력한다.
넷째 줄에는 범위를 출력한다.
| 예제 입력 1 5 1 3 8 -2 2 |
예제 출력 1 2 2 1 10 |
| 예제 입력 2 1 4000 |
예제 출력 2 4000 4000 4000 0 |
| 예제 입력 3 5 -1 -2 -3 -1 -2 |
예제 출력 3 -2 -2 -1 2 |
문제풀이
이 문제는 다른 것들은 굉장히 쉬운 입문자용 문제인데 3번 최빈값이 조금 복잡하다.
이걸 어떻게 풀어야 하는지 좀 많이 헷갈렸었다.
1. 산술평균
먼저 산술평균부터 보도록 하겠다.

모든 주어진 모든 값들을 average라는 변수에 더한 후 그 갯수로 나누어준다.
이때 나누는 갯수를 (double) 형으로 변환해서 자연수를 소수로 만들어 준다음 반올림을 한 값을 다시 (int) 형으로 변환하여 평균값을 구해준다.
왜냐하면 문제에서 소수점 첫째 자리에서 반올림한 값을 출력한다고 했기 때문이다.
2. 중앙값

나는 처음엔 이것도 헷갈렸었다.
왜냐하면 갯수가 홀수인 경우엔 중앙값이 있지만 짝수인 경우엔 중앙값이라는게 없지 않는가?
배열을 정렬한 후 갯수/2에 위치한 값을 담았는데 맞아서 굉장히 놀랐다.
언제나 느끼지만 백준 문제에는 설명이 부족한 것 같다.
4. 범위

범위도 뭐 별거 없다. 그냥 정렬된 배열에서 제일 마지막 값과 제일 처음값을 빼주면 된다.
3. 최빈값
드디어 대망의 최빈값이다. 이 문제의 하이라이트라고 봐도 무방한 문제이다.
문제에서는 최빈값을 가장 많이 나타난 수라고 정의하였고 만약 가장 많이 나타난 수가 여러 개일 경우 그 값들 중 두 번째로 작은 값을 구하라고 하였다.
그렇게 하기 위해서는 먼저 가장 많이 나타난 값을 찾아야 한다.

먼저 배열을 정렬한다.

그리고 위 코드를 사용하여 최빈값을 찾는다.
그런데 이렇게 하면 최빈값의 빈도수를 알 수는 있지만 최빈값이나 최빈값들 중 2번째로 작은 값을 알지는 못한다.
따라서 우리는 여러개의 값들을 빈도수대로 저장할 수 있는 자료구조가 필요하다.
그래서 선택한 것이 map 자료구조이다.
map 자료구조를 사용하여 key값엔 빈도수를 value들엔 해당 값을 넣는 것이다.
하지만 빈도수가 여러가지인 값들의 경우 map.put()을 실행할 때마다 value가 바뀌게 되어 여러가지 값들을 저장하지 못한다.
이럴때를 대비하여 아래와 같은 자료구조를 사용할 것이다.
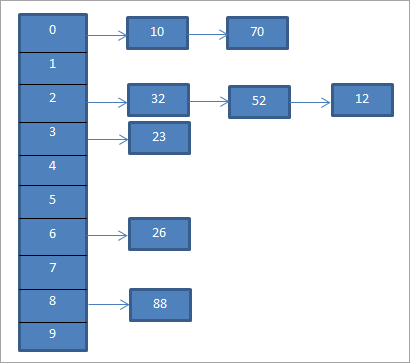
위 구조는 close addressing hash table이라는 아주 생소한 자료구조이다.
이름만 생소하지 구조는 위 그림과 같이 간단하다.
만약 같은 key값의 여러개의 value값들이 존재한다면 위 그림처럼 list로 엮어주는 것이다.

위 그림을 구현하기 위하여 위 코드를 작성한다. 이때 LinkedHashMap을 쓰는 이유는 값을 저장한 순서대로 저장하기 위해서이다.
하지만 그냥 HashMap으로 써도 무방하다. 처음엔 순서대로 저장해야 마지막 값을 빼서 최대 빈도수를 구할 수 있을 줄 알았는데 그런 메소드는 없어서 그냥 maxRep이라는 변수를 이용하여 최대 빈도수를 알아내서 그 값으로 value를 리턴받는 식으로 코딩을 하였다.
HashMap, LinkedHashMap, TreeHashMap을 언제 사용하는지 알고 싶다면
LinkedHashMap
HashMap, TreeMap, LinkedHashMap 키-값 관계로 맵핑하는 경우에 사용하는 클래스에는 Has...
blog.naver.com
이곳으로 가서 확인하면 된다.
그렇게 선언을 한 후 빈도수 1을 키값으로 하는 arraylist를 value값으로 넣어준다.
그리고 초기에 설계했던 반복분에서 다음과 같은 코드들을 추가해준다.

위 코드와 같이 반복문 맨 처음엔 rep에 해당하는 빈도수의 키값에 있는 arrayList에 우리가 조사하는 값이 있는지 없는지를 조사하여 값의 중복 저장을 막는 코드를 넣는다.
그리고 똑같이 해당 값의 빈도수를 조사한 후 해당 빈도수의 키가 없다면 추가한 후 해당 빈도수에 값을 넣고 빈도수가 이미 존재한다면 해당 키값에 해당하는 ArrayList에 값을 넣는다.
이렇게 하면 {빈도수 : 해당 값들}에 해당하는 [1 : N] 관계의 HashTable이 만들어질 것이다.

그리고 위 코드를 이용하여 최다 빈도수인 maxRep을 키 값으로 가지는 ArrayList를 정수 배열로 반환받아서 정렬을 한다.

그리고 위 코드를 이용하여 만약 해당 배열의 값이 1개라면 제일 첫 번째 값을 리턴받고 배열이 여러개라면 여러 개의 값들 중 두 번째로 작은 값을 리턴받으면 문제에서 원하는 최빈값을 구할 수 있다.
Junit 테스트

위 값들을 가지고 실험을 하였고

문제없이 실행되었다.
실행시간

위 코드를 이용하여 문제에서 주어진 500,000개의 4000을 넘지 않는 정수값들을 문자열로 리턴받은 뒤 실험하였더니

평균적으로 0.3~0.4초 정도가 나와서 시간 안에 풀 수 있었다.
소스코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
import java.io.*;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.Map;
public class Main
{
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
public static String statistic() throws IOException {
int n = Integer.parseInt(br.readLine());
int[] nums = new int[n];
for(int i = 0 ; i < n ; i++) nums[i] = Integer.parseInt(br.readLine());
// 1. 산술평균값
int average = 0;
for(int i = 0 ; i < nums.length; i++) {average += nums[i];}
average = (int)Math.round(average / (double)nums.length);
// 2. 중앙값
Arrays.sort(nums);
int middle = nums[nums.length/2];
// 3. 최빈값
Map<Integer, ArrayList<Integer>> mrv = new LinkedHashMap<>();
mrv.put(1,new ArrayList());
int maxRep = 0;
for(int i = 0, rep = 1 ; i < nums.length ; i++)
{
if(mrv.get(rep).contains(nums[i])) continue;
rep = 1;
for (int j = i + 1; j < nums.length; j++) {
if (nums[i] != nums[j]) break;
rep++;
}
maxRep = rep > maxRep ? rep : maxRep;
if(!mrv.containsKey(rep))
{
mrv.put(rep,new ArrayList());
mrv.get(rep).add(nums[i]);
}
else mrv.get(rep).add(nums[i]);
}
Integer[] result = mrv.get(maxRep).toArray(new Integer[0]);
Arrays.sort(result);
if(result.length==1) maxRep = result[0];
else maxRep = result[1];
// 4. 범위
int range = nums[nums.length-1] - nums[0];
return String.valueOf(average) + "\n" + String.valueOf(middle) + "\n" + String.valueOf(maxRep) + "\n" + String.valueOf(range);
}
public static void main(String args[]) throws IOException {
bw.write(statistic());
bw.flush();
bw.close();
}
}
|
cs |
느낀점
뭔가 쉬워보여서 도전했다가 최빈값에서 많이 당황하여 문제를 푸는데 좀 시간이 걸렸던 것 같다.